
Lo scorso 29/08/2023, Emiliano Zeppa – Infrastructure Security Engineer in PagoPA – ha pubblicato un articolo dal titolo: “Sicurezza dei servizi: la gestione dei log in PagoPA” nel quale descrive con un taglio tecnico “…Il Sistema di Gestione degli Eventi di Sicurezza che utilizziamo in PagoPA per il monitoraggio delle infrastrutture operative…“
Chi mi conosce, sa che “logging” e “monitoring” sono due temi che mi stanno particolarmente a cuore. Ho anche avuto il piacere di parlarne pubblicamente in diverse occasioni, fra le quali questa:
- “NET/SYS/APP monitoring in un medio Ateneo Italiano (nel 2019)” – Damiano Verzulli al WorkShop GARR 2019, il 09/10/2019 – [slide] – [stream]
Ho quindi iniziato a leggere l’articolo, curioso di compararlo al contesto classico che più mi è familiare: quello di un Ateneo di medie dimensioni.
Ho subito trovato poco opportuni i numerosi riferimenti al vendor (citato 8 volte) ed al prodotto utilizzato (citato 17 volte): mi chiedo che valore abbia tale informazione nel contesto dell’articolo… salvo quello di fare “pubblicità”… Ma NON è questo l’elemento su cui voglio soffermarmi…
Procedendo nella lettura, sono arrivato alle conclusioni. In particolare, a questo passaggio:

Dunque, 80 milioni di eventi al giorno, con traffico di circa 92 GB/giorno e retention tali da richiedere ~25TB di storage.
Si tratta di numeri certamente significativi, che colgono subito l’attenzione anche del lettore “tecnico”, che spessissimo (quasi sempre…) non ha familiarità con contesti di tale estensione.
Ma *NON* è il mio caso.
Ho ben presente la dimensione e la complessità di infrastrutture che generano quei flussi di dati. Ne ho gestita una per molti anni (descritta qui: [slide][stream]). Conosco almeno 15 tecnici universitari che, nei rispettivi Atenei, hanno a che fare con infrastrutture ICT che generano volumi analoghi (a volte, anche superiori). In ambito SIEM, ho chiaramente stampata nel cervello una frase che Simone Bonetti –tecnico attivo presso il CERT di UniBO– scrisse diversi anni fa nell’ambito di una delle numerose “chiacchiere da Bar” fatte in GARRLab:
“il SIEM (open/closed non fa differenza) è una enorme lente d’ingrandimento: come ogni sistema di analisi vi fa vedere cose che voi umani non volete vedere :-D….“
(cfr. slide 10 di questa presentazione, su GARRLab )
N.B.: Simone parlerà di monitoring in ambito cybersecurity in un talk specifico della ntopConf 23, il prossimo 22/09/23. Se siete ancora in tempo e vi va di fare un salto a Pisa, fateci un pensierino…
La (non) distinzione fra “open” e “closed” fatta da Simone NON è casuale: da diversi anni, ormai, la maturità delle soluzioni disponibili con licenze Open-Source ha raggiunto livelli di assoluto rilievo. Il problema NON è (più) il SIEM in quanto tale: il problema è quello di fargli arrivare i dati necessari + organizzare quanto necessario per filtrare via il rumore + organizzare quanto necessario per storicizzare quello che resta e, in ultimo, predisporre quanto necessario all’analisi che si vuole effettuare.
Di tutto ciò, la componente SIEM rappresenta solo una parte. Certamente importante; ma assolutamente non sufficiente.
Diversi sono stati i test-bed di Wazuh [GPL v2] e di Security Onion [EL v2] o anche di ntopng[ GPL_v3) che ho seguito indirettamente, ed io stesso ho seguito i deployment di diverse infrastrutture basate sulle componenti software open-source sottostanti (a partire da elasticsearch / opensearch ) e su una pluralità di tecnologie a corredo, necessarie per… costruire la lente e guardarci attraverso.
L’uso di tecnologie open-source *NON* ha mai rappresentato un limite.
Se un limite c’è stato, è sempre stato causato da altri fattori
Alla luce di tutto ciò, dopo aver riflettuto sui numeri riportati da Emiliano Zeppa nel suo articolo, ho sentito diversi amici/colleghi e chiesto loro informazioni circa la “dimensione” della propria infrastruttura: il mio obiettivo era quello di trovarne una che fosse paragonabile, dimensionalmente, a quella citata da PagoPA.
Dopo diversi tentativi e qualche ora di attesa, è arrivato questo:
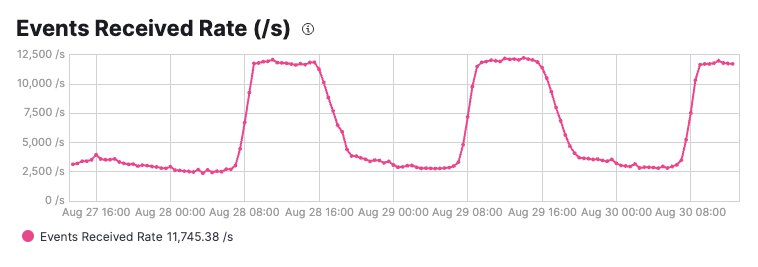
È uno screenshot recuperato dal “tecnico” di un medio Ateneo, generato a partire dagli eventi ricevuti nel periodo indicato (dal 27/08/2023 a meta’ mattina del 30/08 – giorno in cui ho iniziato a scrivere questo articolo).
Il grafico parla da se: l’infrastruttura allestita per analizzare gli eventi, riceve, al bordo, un flusso costante di circa 2.500 eventi AL SECONDO, con picchi nelle fasce lavorative che arrivano a 12.500.
Siamo su valori ben superiori a 925 eventi/secondo (che corrispondono a 80M di eventi/giorno, di media). E sono superiori anche al “x10”, assumendo che un picco sia alto ~10 volte il valore medio.
L’infrastruttura che ha prodotto la curva disegnata qui sopra, RICEVE gli eventi indicati, li FILTRA per eliminare quelli palesemente inutili ai fini dell’analisi che si vuole condurre, e ARCHIVIA il risultato post-filtro al fine di renderlo fruibile per le attivita’ di analisi cui si è interessati. Dunque, in archivio finiscono un numero ridotto di eventi.
Di quanti eventi “archiviati” parliamo?

Dunque, in un Ateneo medio… dove lavora un tecnico pressoché sconosciuto, quello stesso tecnico gestisce una infrastruttura che ha memorizzati circa 2.1 G eventi, per 4.4 TB di dati. Aggiungo –per il lettore più attento– che tale volume è quello generato con una retention dell’ordine dei “6 giorni” (ossia: è il volume dei dati ARCHIVIATI negli ultimi 6 giorni).
Rispetto alla “frequenza” di injestion, ossia alla quantità di dati che questa infrastruttura è in grado di gestire, i numeri a metà mattina (cui gli screenshot di riferiscono) erano questi:

~79M di documenti, per 201 GB di occupazione e un rate di archiviazione di circa 305 eventi/secondo.
È interessante osservare –sempre per il lettore piu’ attento– che la quantita’ di dati archiviati (quei 2.1 G documenti) è una parte molto inferiore al numero totale di eventi che arrivano all’infrastruttura. In altri termini: dei ~12.500 eventi che stavano arrivando (al momento di quegli screenshot), ogni secondo, soltano 305 venivano effettivamente “catturati” e “storicizzati” per analisi successive. Ogni secondo, chiaramente.
L’infrastruttura complessiva che gestisce tutto tale ambaradan *NON* rappresenta una eccezione unica e particolare nello scenario UNIV nazionale. Ve ne sono di simili, tutte accomunate da una caratteristica: essere 100% “on-premise” e basate 100% su soluzioni Open-Source
Dunque, a questo punto dovrebbe essere chiaro con quali occhi leggo l’articolo che descrive l’infrastruttura allestita in PagoPA.
Proseguendo nella lettura, arrivo al passaggio fondamentale. Questo:

La mia convinzione, forte delle esperienze che in molte UNIV diversi tecnici hanno maturato proprio lavorando con le infrastrutture “cloud” dei principali cloud-provider, e delocalizzando su tali infrastrutture parti piu’ o meno consistenti del proprio workload… è esattamente opposta: infrastrutture “on-premise” hanno un TCO inferiore alle analoghe infrastrutture cloud.
La mia convizione è esattamente opposta: l’on-prem ha un TCO più basso
Il tema è delicato, non solo perché –scommetto– le cifre in ballo nel caso PagoPA non sono trascurabili, ma soprattutto perché una formulazione del genere, che privilegia una scelta “cloud” rispetto ad una “on-prem” senza minimamente entrare nel merito della scelta stessa, rischia di creare un pericoloso precedente per tutti coloro che –a differenza di chi scrive– non hanno gli strumenti per dimensionare e valutare le proprie esigenze e, di conseguenza, finiscono per essere trainati dalle scelte di PagoPA (“Ma se PagoPA è andata in cloud… allora pure noi dobbiamo andarci… Se loro dicono che è piu’ economico… allora vuol dire che sara’ piu’ economico anche per noi“).
Di nuovo, mi viene in mente il parallelo con il mondo UNIV.
Unico nel panorama nazionale, per affrontare l’emergenza COVID il Politecnico di Torino scelse coraggiosamente di erogare i servizi di Didattica a Distanza utilizzando “soluzioni on-prem” piuttosto che quelle blasonate “in-cloud”. Fra le varie ripercussioni tecnologiche che tale scelta ha comportato sul piano tecnico, c’è stata la necessità di acquisire “storage” per la memorizzazione degli stream audio/video relativi alle lezioni.
In termini economici, i funzionari del Politecnico effettuarono una analisi dettagliata dei costi, sia nello scenario “on-prem”, sia in quello “cloud” (nota: sarebbe interessante riflettere sul tema dell’archiviazione degli stream delle lezioni in epoca COVID, anche in tutti quegli altri contesti che hanno utilizzato soluzioni ‘cloud’. Dove sono, attualmente, tali registrazioni, e quanti costi generano? …ma stiamo uscendo fuori tema).
Uno spaccato di tale processo decisionale e di tutte le variabili di cui si tenne conto, è stato presentato da Enrico Venuto al Workshop GARR 2022, nel suo intervento dal titolo:
- “In-Cloud o In-House? L’importanza delle competenze per scegliere bene” – di Enrico Venuto – WorkShop GARR 2022 – [slide] [stream]
Prima di venire –io– attaccato sulla base del fatto che il caso d’uso descritto da Enrico Venuto è drasticamente diverso da quello di PagoPA e che, quindi, i due scenari sono difficilmente comparabili… segnalo che il problema che voglio evidenziare *NON* è quello determinato dalle risultanze dell’analisi di Venuto (che comunque, nella slide 17, segnala come NEL SUO CASO SPECIFICO, lo storage su cloud costa “da 83 a 165 volte di piu’” rispetto all’on-prem), ma piuttosto nel fatto che l’Ing. Venuto ha dettagliatamente svolto la comparazione ed è giunto ad un risultato.
È evidente, ed è anche naturale, che si può essere più o meno d’accordo con l’analisi di Venuto. La si potrà condividere, oppure la si potrà additare come carente su alcuni ambiti. Resta comunque il fatto che –proprio perché presente e dettagliata nelle sue slide e nella sua presentazione– è possibile discuterne e sindacarla. Cosa che non è affatto possibile nello scenario di PagoPA, in quanto nessun dettaglio è disponibile salvo un generico: “Un’infrastruttura on-premise sarebbe piu’ costosa“
Da persona direttamente interessata alle dinamiche ICT del nostro Paese (di cui PagoPA rappresenta una componente estremamente importante), da persona che ritiene di conoscere abbastanza bene le dinamiche relative al tema del “Monitoring” e del “Log Management” di infrastrutture mediamente complesse e, soprattutto, da persona estremamente attenta e vicina a tutte le dinamiche del mondo Open-Source, chiedo all’Ing. Zeppa di dettagliare gli aspetti economici che –a suo dire– vedono vantaggiosa la soluzione proprietaria implementata su cloud in PagoPA, rispetto a soluzioni “on-premise” basate su piattaforme open-source.
Un confronto aperto e scevro da preconcetti –come quello che sono certo ne deriverebbe– su questo tema, risulterebbe di estremo aiuto a tutti quei funzionari pubblici che, purtroppo… hanno un problema, ma non riescono a trovare una soluzione 🙁
Bell’articolo Damiano, complimenti!
Cercherò di vedere anche gli stream, che mi sembrano interessanti soprattutto .